Sprach-KI
Entwickelt für KI-Agenten
Wir entwickeln dateneffiziente Foundational Text-to-Speech (TTS) Modelle, die als Infrastruktur für Vertical Voice AI Agents dienen. Wo generische Modelle oft an komplexen Edge Cases, Dialekten oder Fachjargon scheitern, lernen unsere Modelle diese spezifischen Betonungsmuster mit sehr kleinen Datensätzen in extrem hoher Qualität. So liefern wir Vertical AI Startups ihren TTS-Layer mit unter 200ms Latenz, bei geringeren Kosten und deutlich natürlicherer Betonung als die Konkurrenz.
Hören Sie selbst
Testen Sie unser V0-Modell, das für geringe Latenz und Kosteneffizienz entwickelt wurde. Geben Sie Ihren Text unten ein, um eine Audio-Vorschau zu generieren.
Tontaube V0 ist ein grundlegendes Sprach-KI-Modell. Verbesserte Versionen für App und API folgen in Kürze.
Long-form narration samples
Experience extended passages in English and German from Tontaube, the world's most natural-sounding model for audiobooks.
Mit Tontaube entwickeln
Eine schnelle, kostengünstige Sprachgenerierungs-API, die auf unserer Architektur basiert. Klonen Sie jede Stimme aus einer einzigen Audiodatei und generieren Sie Langform-Sprache mit 10-facher Echtzeitgeschwindigkeit.
- 200.000 kostenlose Zeichen bei Registrierung
- 5 $ pro Million Zeichen
- Pay-as-you-go mit Enterprise-Tarifen
- Benutzerdefinierte Stimmen (bald verfügbar)
- ~200ms Latenz für Unternehmenskunden
import tontaube
with tontaube.Client(api_key="ttb_live_...") as client:
speakers = client.list_speakers()
for speaker in speakers:
print(f"{speaker.name} ({speaker.voice_style}), id: {speaker.id}")
response = client.generate_speech(
text="I am here to help you with your project. Tell me what we are building today, and I will get right to work.",
speaker_id=speakers[0].id,
temperature=0.8,
)
with open("speech.opus.m4a", "wb") as f:
f.write(response.content)
print(f"Duration: {response.audio_duration}s, Cost: ${response.cost_usd}")
print("Result saved to speech.opus.m4a")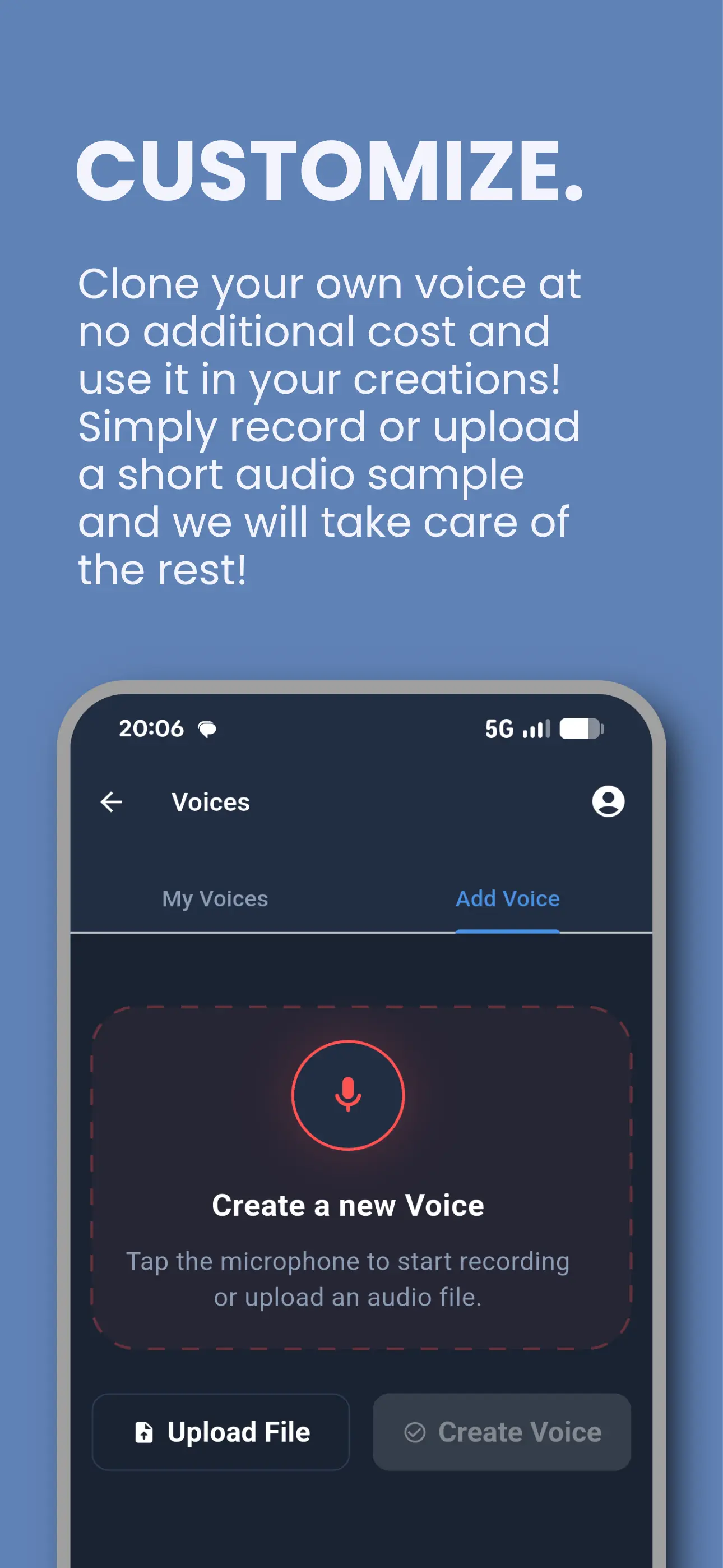
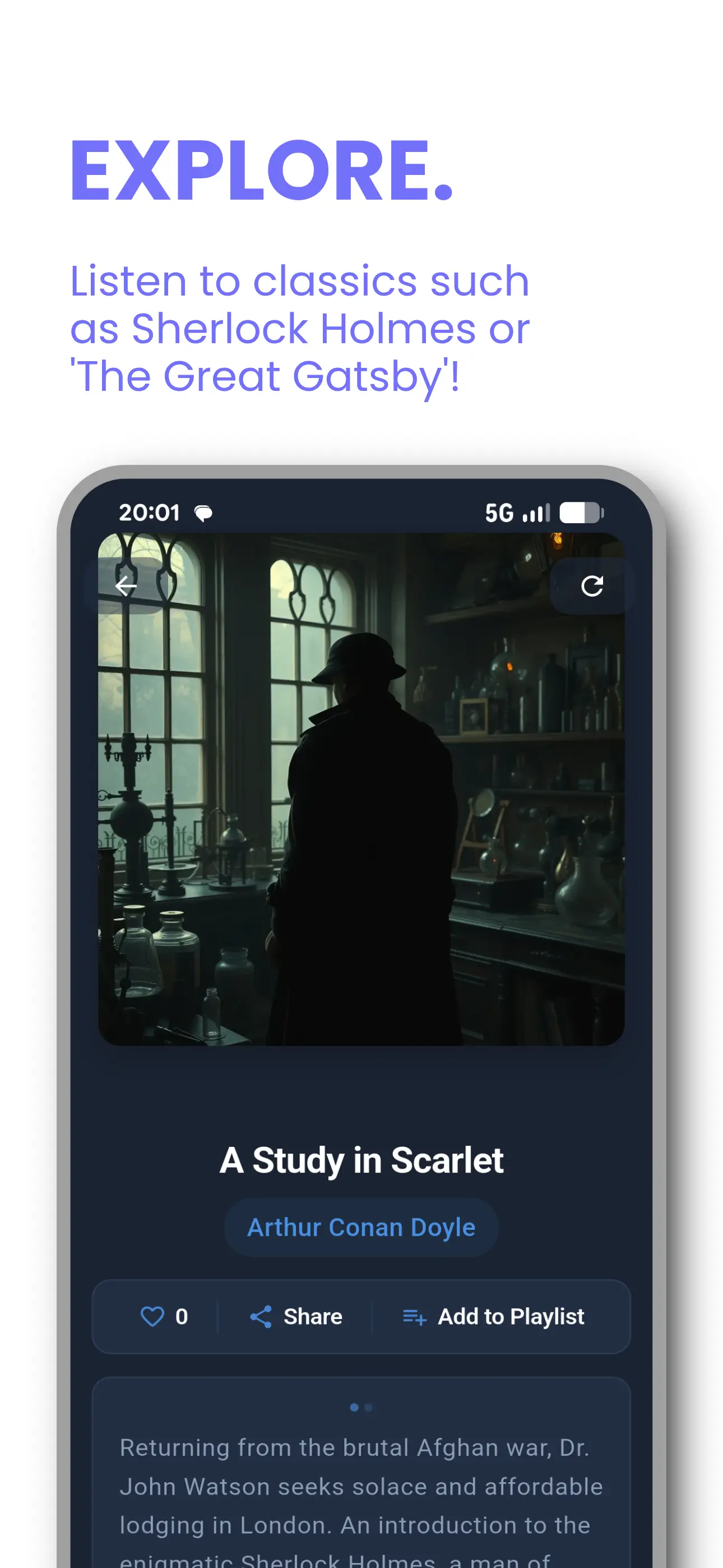

Tontaube für iOS & Android
Unsere Hörbuch- und Voice-Cloning-App — bereits in den Händen tausender Hörer. Konvertieren Sie jedes Dokument in Audio, klonen Sie Ihre Stimme und streamen Sie aus einer Public-Domain-Bibliothek.
- PDF-, EPUB- & Dokumentenkonvertierung
- Kostenloses Voice Cloning
- Über 30.000 KI-Hörbücher
Interesse an einer Investition?
Wir haben die Architektur im Prototypenstadium bewiesen und suchen Investitionen, um Rechenleistung, Daten und das Team zu skalieren.