Voice AI
Built for AI Agents
Tontaube builds foundation text-to-speech models for the next generation of voice AI agents. Sub-200ms latency, on-device deployment, and naturalness that even holds up on long-form narration.
Hear It For Yourself
Test our V0 model, designed for low latency and cost efficiency. Converse with our Voice AI Agent or type your text to synthesize audio...
Tontaube V0 is a foundational voice AI model. Improved versions are coming to the app and API soon.
Long-form narration samples
Experience extended passages in English and German from Tontaube, the world's most natural-sounding model for audiobooks.
Build with Tontaube
A high-speed, cost-efficient voice generation API powered by our architecture. Clone any voice from a single audio file and generate long-form speech at 10× real-time speed.
- 200,000 free characters on sign-up
- $5 per million characters
- English & German · more languages coming soon
- Pay-as-you-go with enterprise plans
- Custom voices (coming soon)
- ~200ms latency for enterprise customers
import tontaube
with tontaube.Client(api_key="ttb_live_...") as client:
speakers = client.list_speakers()
for speaker in speakers:
print(f"{speaker.name} ({speaker.voice_style}), id: {speaker.id}")
response = client.generate_speech(
text="I am here to help you with your project. Tell me what we are building today, and I will get right to work.",
speaker_id=speakers[0].id,
temperature=0.8,
)
with open("speech.opus.m4a", "wb") as f:
f.write(response.content)
print(f"Duration: {response.audio_duration}s, Cost: ${response.cost_usd}")
print("Result saved to speech.opus.m4a")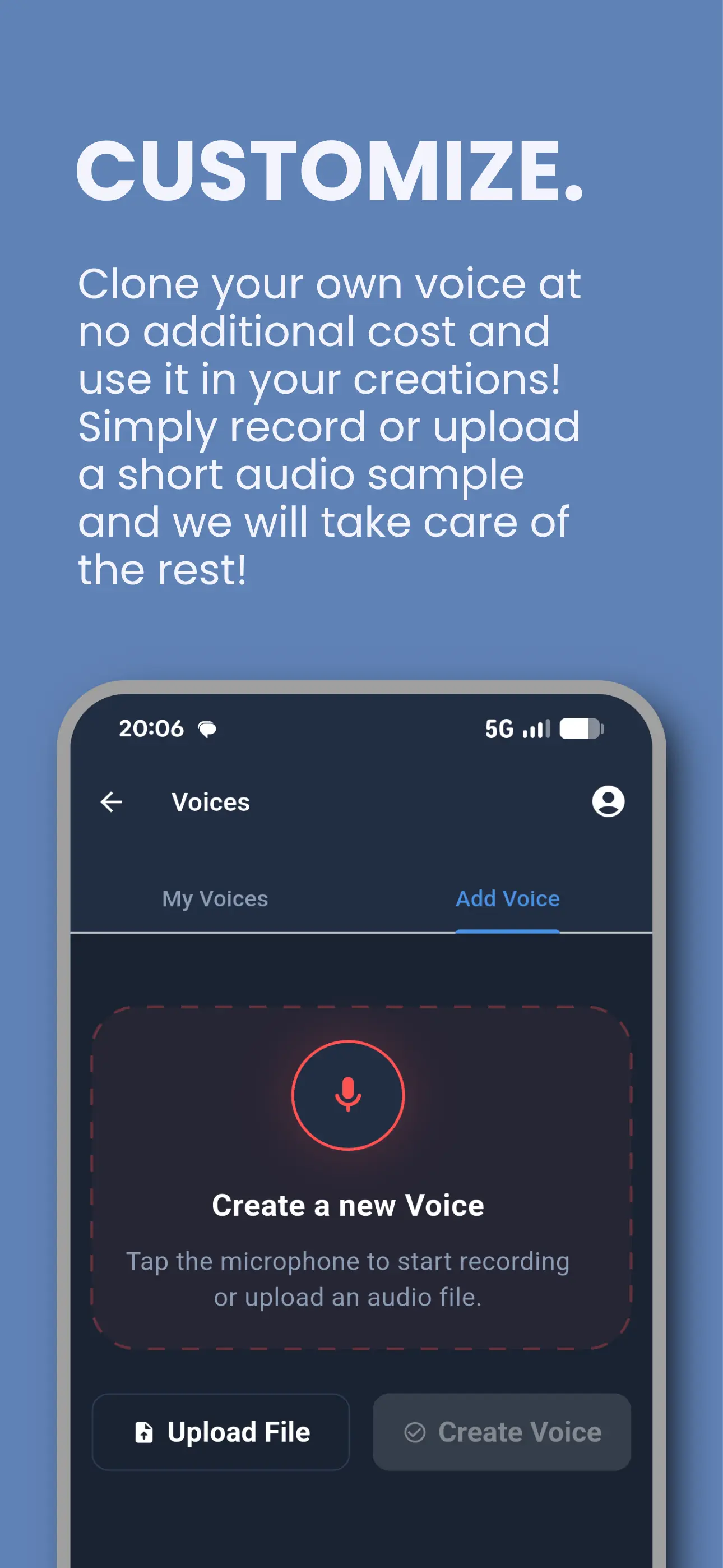
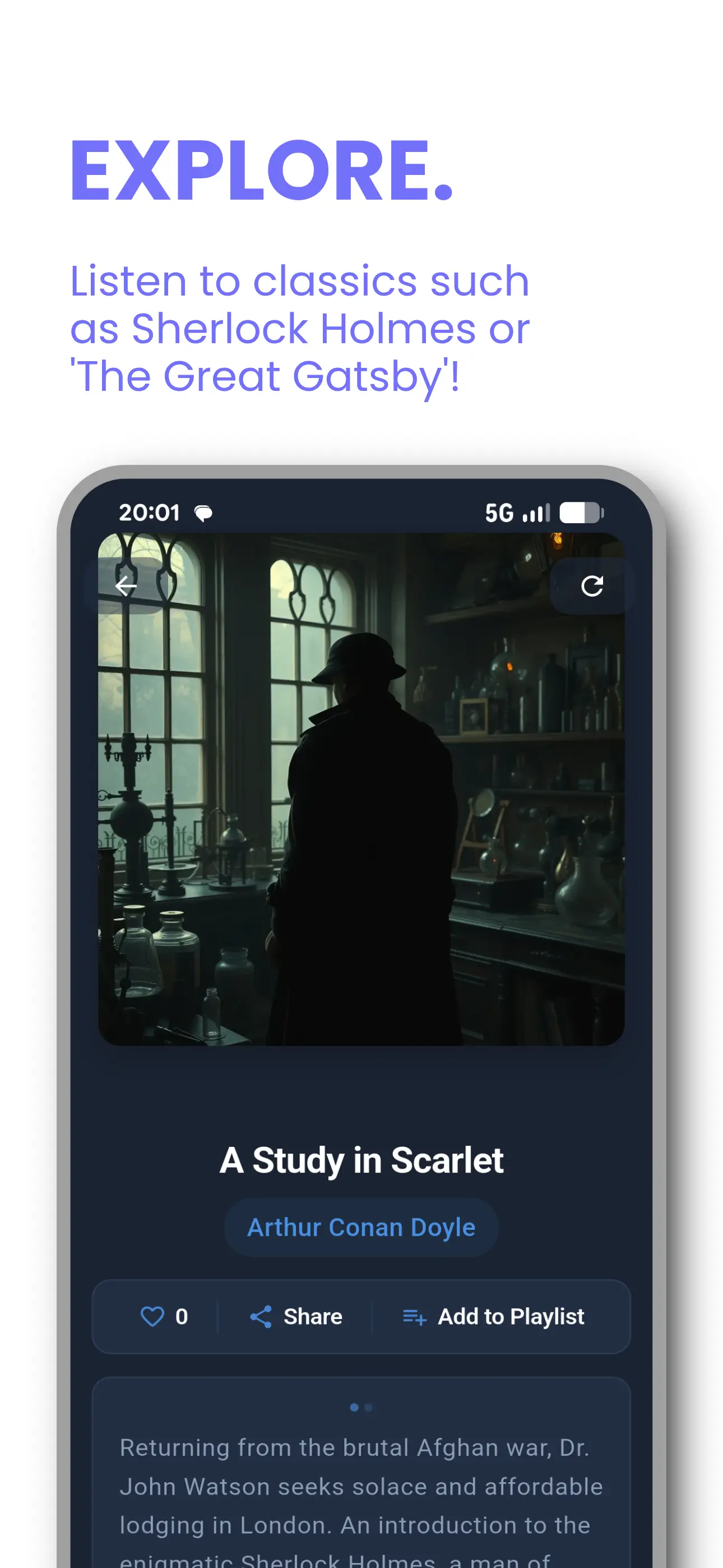

Tontaube for iOS & Android
Our audiobook and voice cloning app — already in the hands of thousands of listeners. Convert any document to audio, clone your voice, and stream from a public domain library.
- PDF, EPUB & document conversion
- Free voice cloning
- 30,000+ AI audiobooks
Interested in Investing?
We've proven the architecture at prototype scale and are seeking investment to scale compute, data, and the team.