基础语音AI
语音AI
专为AI代理构建
早期实验表明,与行业标准方法相比,效率显著提高。
Tontaube V0 · 现已推出
亲耳聆听
测试我们的 V0 模型,专为低延迟和高成本效益而设计。在下方输入文本以生成音频样本。
Enter Text
Tontaube V0 是一个基础语音 AI 模型。改进版本即将上线应用和 API。
Long-form narration samples
Experience extended passages in English and German from Tontaube, the world's most natural-sounding model for audiobooks.
使用 Tontaube 进行构建
由我们架构驱动的高速、高性价比语音生成 API。通过单个音频文件克隆任何声音,并以 10 倍实时速度生成长篇语音。
- 200,000 注册即享免费字符
- 每百万字符5美元
- 按需付费,并提供企业套餐
- 定制声音(即将推出)
- 企业客户延迟约200毫秒
Python
Available on PyPI
import tontaube
with tontaube.Client(api_key="ttb_live_...") as client:
speakers = client.list_speakers()
for speaker in speakers:
print(f"{speaker.name} ({speaker.voice_style}), id: {speaker.id}")
response = client.generate_speech(
text="I am here to help you with your project. Tell me what we are building today, and I will get right to work.",
speaker_id=speakers[0].id,
temperature=0.8,
)
with open("speech.opus.m4a", "wb") as f:
f.write(response.content)
print(f"Duration: {response.audio_duration}s, Cost: ${response.cost_usd}")
print("Result saved to speech.opus.m4a")2.33%
Seed-TTS WER
per row mean, clipped at 100%
94–97%
GMOS prosody wins
vs on-device tier (NeuTTS Air, Nano, Kani TTS 2)
150–200 ms
Server latency
time to first audio chunk on a single GPU
On-Device
Near real-time on Pixel 8
CPU inference — no GPU required
现已可用
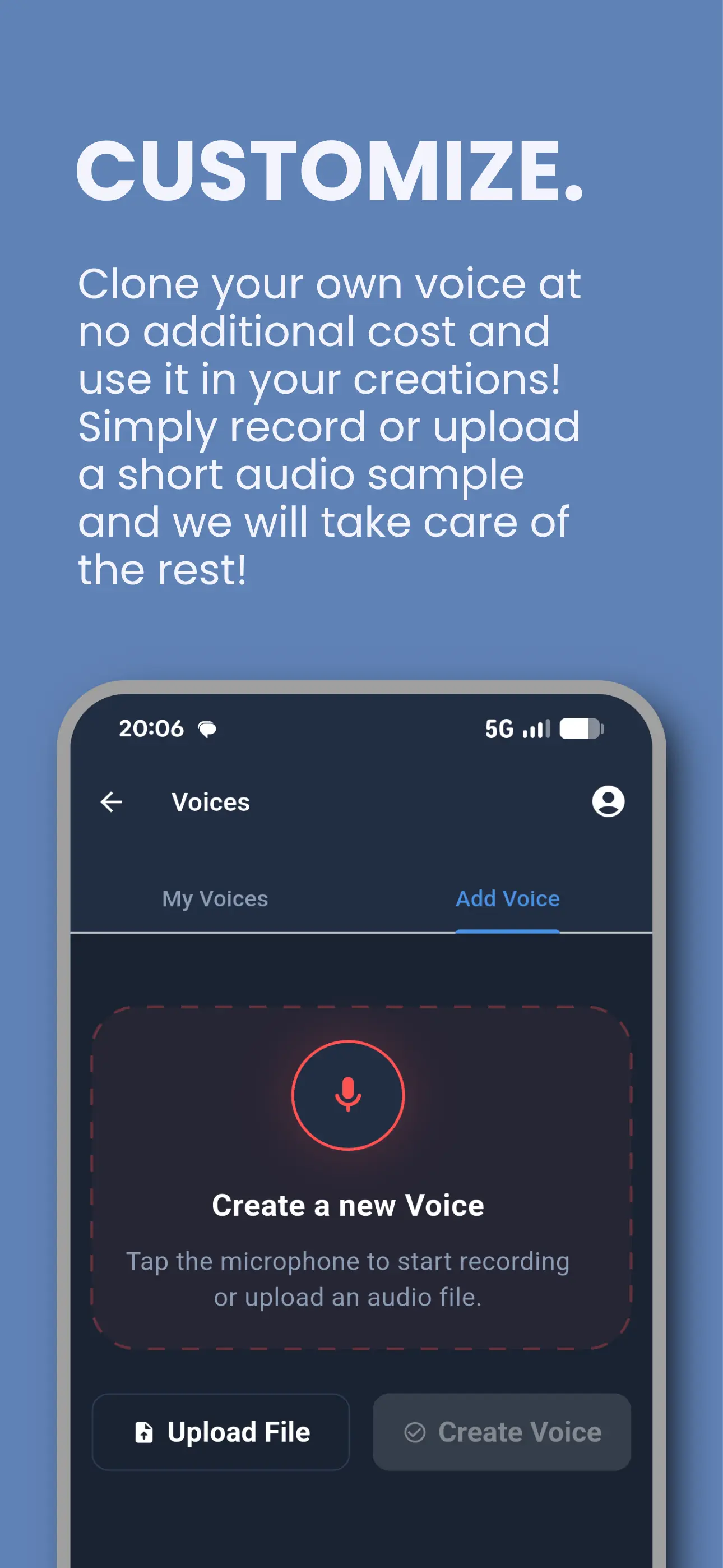
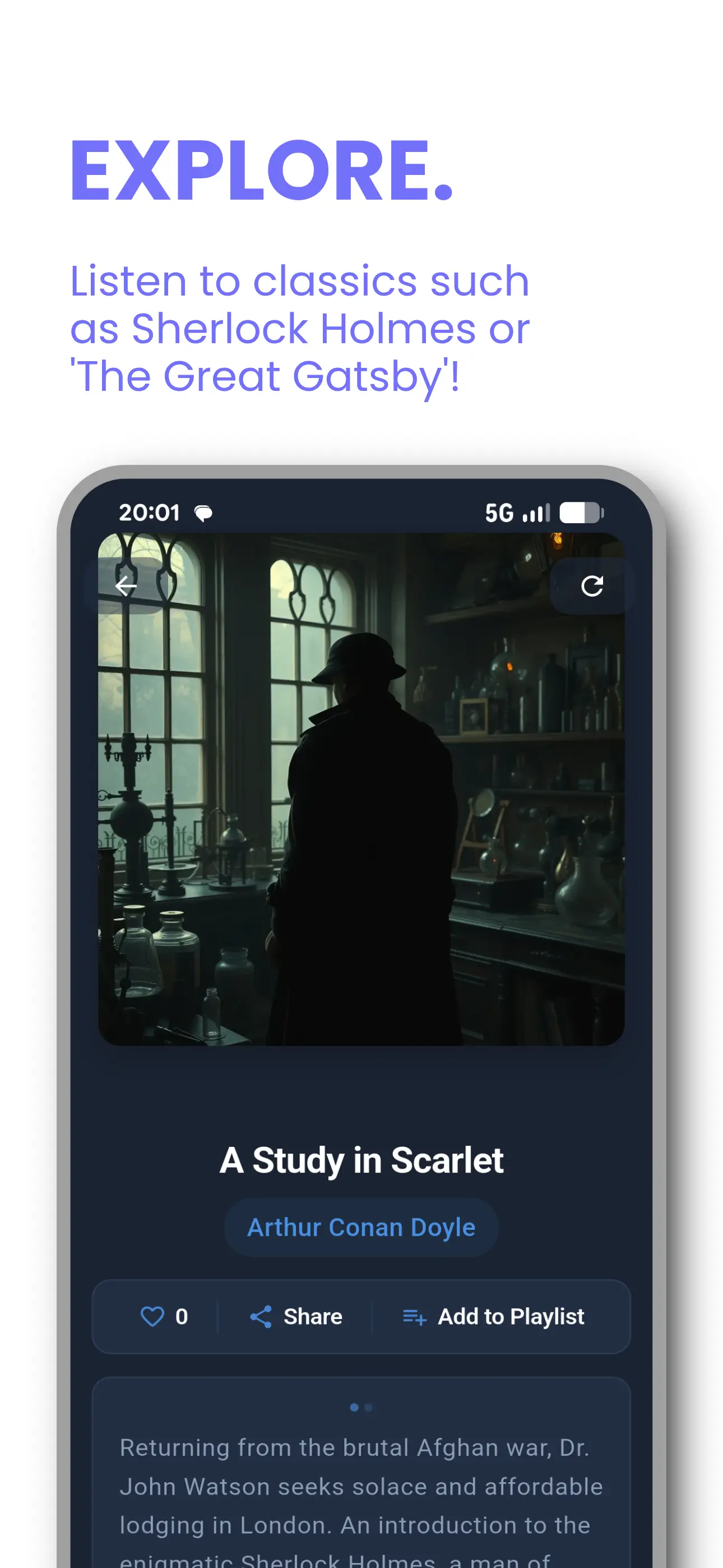

Tontaube 适用于 iOS 和 Android
我们的有声读物和声音克隆应用 — 已有数千名听众使用。将任何文档转换为音频,克隆您的声音,并从公共领域库中进行流式传输。
- PDF、EPUB 及文档转换
- 免费声音克隆
- 30,000+ 部AI有声读物
对投资感兴趣?
我们已在原型规模上验证了该架构,目前正在寻求投资以扩展计算、数据和团队。