IA Vocale
Conçue pour les Agents IA
Premières expériences montrant des gains d'efficacité significatifs par rapport aux approches standard de l'industrie.
Écoutez par vous-même
Testez notre modèle V0, conçu pour une faible latence et une rentabilité optimale. Saisissez votre texte ci-dessous pour générer un échantillon audio.
Tontaube V0 est un modèle d'IA vocale fondamental. Des versions améliorées arriveront bientôt sur l'application et l'API.
Long-form narration samples
Experience extended passages in English and German from Tontaube, the world's most natural-sounding model for audiobooks.
Développez avec Tontaube
Une API de génération vocale rapide et économique, propulsée par notre architecture. Clonez n'importe quelle voix à partir d'un seul fichier audio et générez de la parole longue à une vitesse 10 fois supérieure au temps réel.
- 200 000 caractères gratuits à l'inscription
- 5 $ par million de caractères
- Paiement à l'utilisation avec des plans d'entreprise
- Voix personnalisées (bientôt disponible)
- Latence d'environ 200 ms pour les clients entreprises
import tontaube
with tontaube.Client(api_key="ttb_live_...") as client:
speakers = client.list_speakers()
for speaker in speakers:
print(f"{speaker.name} ({speaker.voice_style}), id: {speaker.id}")
response = client.generate_speech(
text="I am here to help you with your project. Tell me what we are building today, and I will get right to work.",
speaker_id=speakers[0].id,
temperature=0.8,
)
with open("speech.opus.m4a", "wb") as f:
f.write(response.content)
print(f"Duration: {response.audio_duration}s, Cost: ${response.cost_usd}")
print("Result saved to speech.opus.m4a")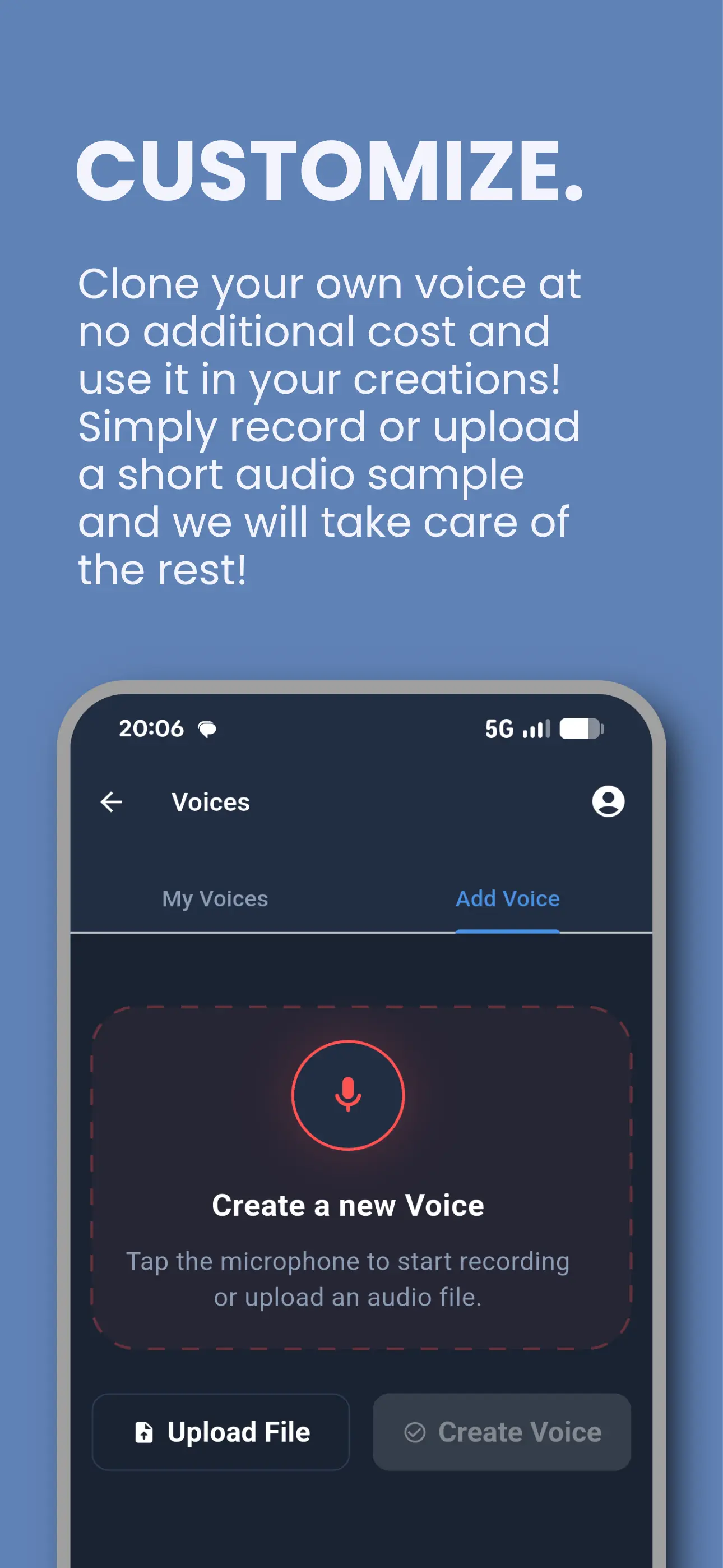
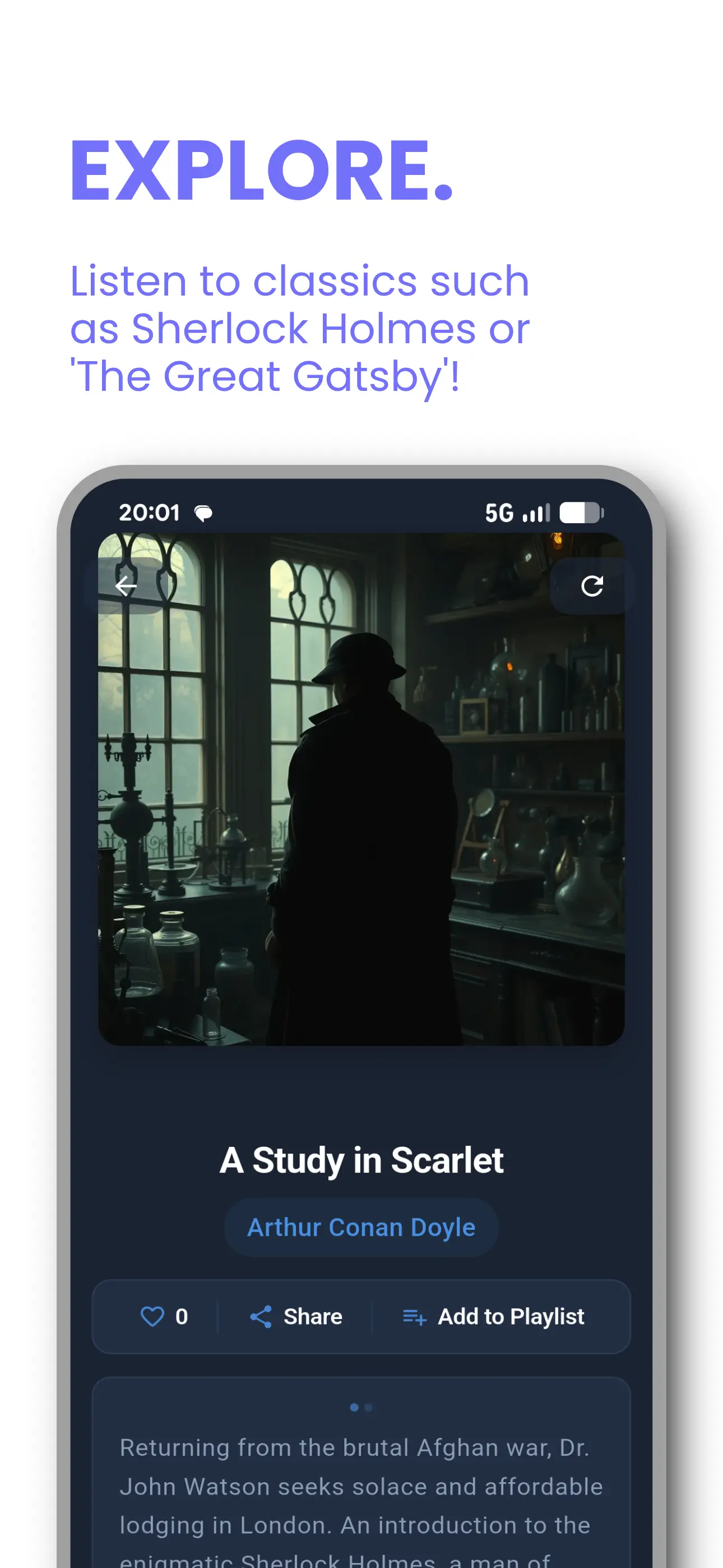

Tontaube pour iOS et Android
Notre application de livres audio et de clonage vocal — déjà entre les mains de milliers d'auditeurs. Convertissez n'importe quel document en audio, clonez votre voix et diffusez depuis une bibliothèque du domaine public.
- Conversion de documents PDF, EPUB et autres
- Clonage vocal gratuit
- Plus de 30 000 livres audio IA
Intéressé par l'investissement ?
Nous avons prouvé l'architecture à l'échelle du prototype et recherchons des investissements pour faire évoluer le calcul, les données et l'équipe.