الذكاء الاصطناعي الصوتي
مصمم لوكلاء الذكاء الاصطناعي
تجارب مبكرة تظهر مكاسب كبيرة في الكفاءة مقارنة بالأساليب القياسية في الصناعة.
استمع بنفسك
اختبر نموذجنا V0، المصمم لتقديم زمن استجابة منخفض وكفاءة في التكلفة. اكتب نصك أدناه لإنشاء عينة صوتية.
Tontaube V0 هو نموذج أساسي للذكاء الاصطناعي الصوتي. ستتوفر إصدارات محسّنة في التطبيق وواجهة برمجة التطبيقات قريبًا.
Long-form narration samples
Experience extended passages in English and German from Tontaube, the world's most natural-sounding model for audiobooks.
صمم باستخدام Tontaube
واجهة برمجة تطبيقات عالية السرعة وفعالة من حيث التكلفة لتوليد الصوت، مدعومة ببنيتنا. استنسخ أي صوت من ملف صوتي واحد وقم بإنشاء كلام طويل بسرعة 10 أضعاف السرعة الحقيقية.
- 200,000 حرف مجاني عند التسجيل
- 5 دولارات لكل مليون حرف
- الدفع حسب الاستخدام مع خطط للمؤسسات
- أصوات مخصصة (قريباً)
- زمن انتقال ~200 ميلي ثانية لعملاء المؤسسات
import tontaube
with tontaube.Client(api_key="ttb_live_...") as client:
speakers = client.list_speakers()
for speaker in speakers:
print(f"{speaker.name} ({speaker.voice_style}), id: {speaker.id}")
response = client.generate_speech(
text="I am here to help you with your project. Tell me what we are building today, and I will get right to work.",
speaker_id=speakers[0].id,
temperature=0.8,
)
with open("speech.opus.m4a", "wb") as f:
f.write(response.content)
print(f"Duration: {response.audio_duration}s, Cost: ${response.cost_usd}")
print("Result saved to speech.opus.m4a")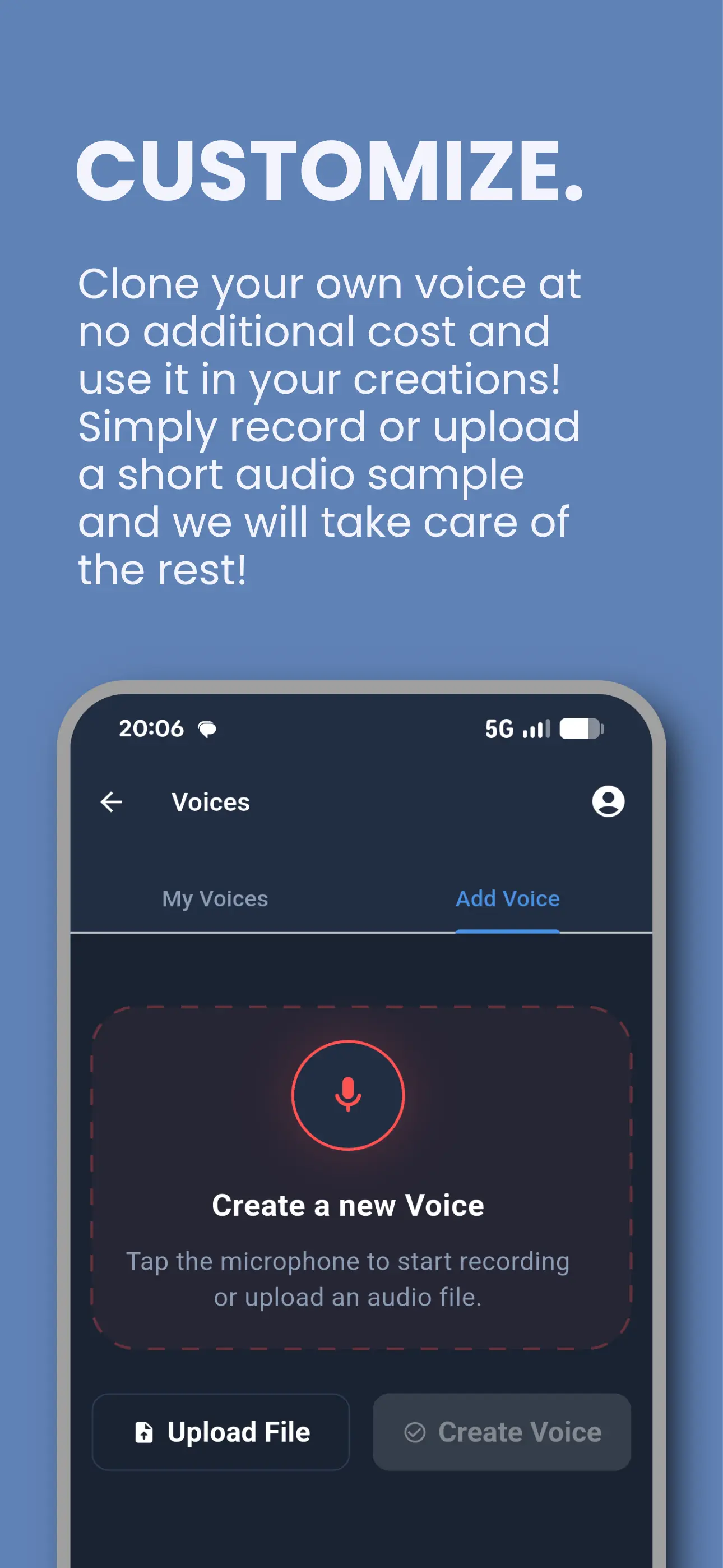

Tontaube لنظامي iOS و Android
تطبيقنا للكتب الصوتية واستنساخ الصوت - بين أيدي الآلاف من المستمعين بالفعل. قم بتحويل أي مستند إلى صوت، واستنسخ صوتك، وقم بالبث من مكتبة المجال العام.
- تحويل مستندات PDF و EPUB وغيرها
- استنساخ صوت مجاني
- أكثر من 30,000 كتاب صوتي بالذكاء الاصطناعي
هل أنت مهتم بالاستثمار؟
لقد أثبتنا جدوى البنية المعمارية على نطاق النموذج الأولي ونسعى للحصول على استثمار لتوسيع نطاق الحوسبة والبيانات والفريق.